Active speech synthesis based on listener perceptual modeling
This work was supported by JSPS KAKENHI Grant Number 18J22090. (Apr. 2018 -- Mar. 2021)
Research Project 1: Generative-adversarial-network-based text-to-speech synthesis using auditory-sensitive features
Research highlights:
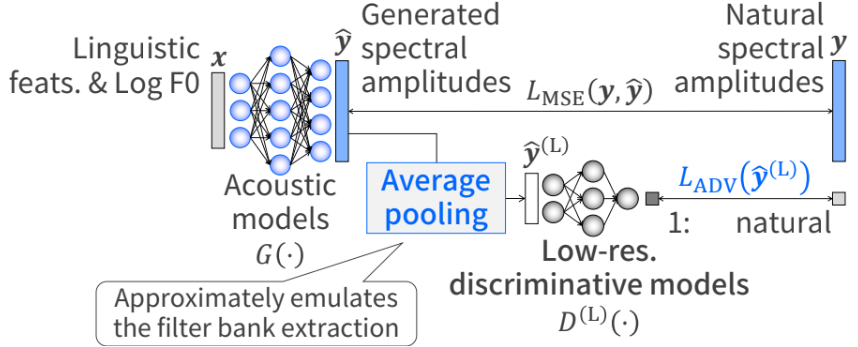
We propose novel training algorithms for vocoder-free text-to-speech (TTS) synthesis using STFT spectra based on generative adversarial networks (GANs).
We demonstrate that using GANs with the original-frequency-resolution amplitude spectra degrades the synthetic speech quality.
We show that the proposed low-frequency-resolution GANs improves the synthetic speech quality.
We also show that using the inverse mel scale for the proposed algorithm further improves the synthetic speech quality.
Proposed GAN-based TTS. We introduce an average-pooling to the training for obtaining low-dimensional features representing spectral envelopes that are important in human speech perception.
Datasets:
We used subsets (4,007 utterances) of the JSUT corpus.
Speech samples (in Japanese, DNN-based TTS):
NAT: Natural speech.
MSE: Minimizing mean squared error.
GAN: Proposed GAN-based training.
Method
Sample 1
Sample 2
Sample 3
NAT:
MSE:
GAN:
References:
Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari,
"Vocoder-free text-to-speech synthesis incorporating generative adversarial networks using low-/multi-frequency STFT amplitude spectra,"
Computer Speech and Language, Vol. 58, pp. 347--363, Nov. 2019. (ScienceDirect)
Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari,
"Text-to-speech synthesis using STFT spectra based on low-/multi-resolution generative adversarial networks,"
Proc. ICASSP, pp. 5299--5303, Alberta, Canada, Apr. 2018. (PDF, Poster)
Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari,
"Adversarial DNN-based speech synthesis using multi-frequency resolution STFT spectra,"
Proc. ASJ, Spring meeting, 3-8-14, pp. 259--262, Mar. 2018. (in Japanese) (PDF, Slide)
Research Project 2: Speaker embedding using crowdsourced subjective inter-speaker similarity
Research highlights:
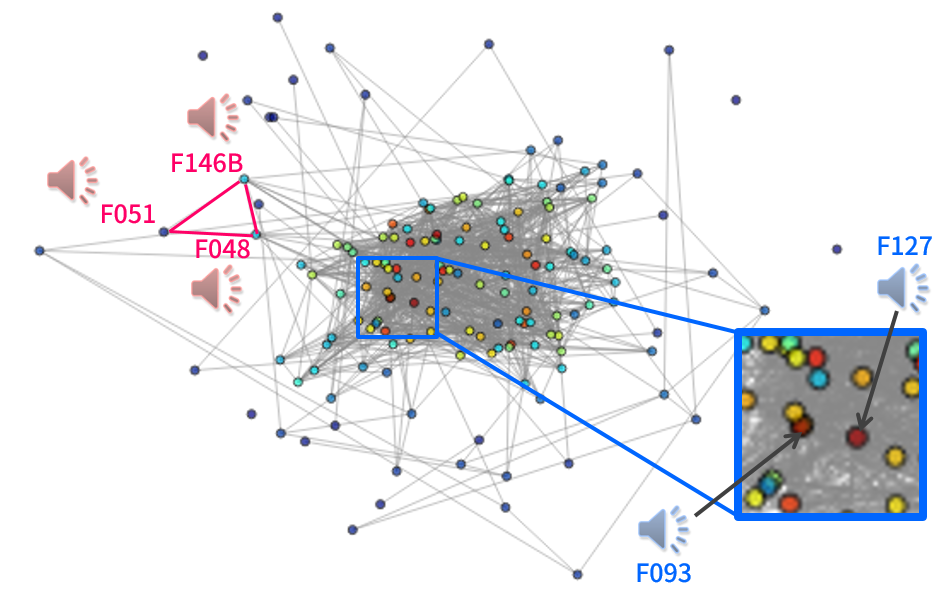
We propose novel training algorithms for speaker embedding considering subjective inter-speaker similarity.
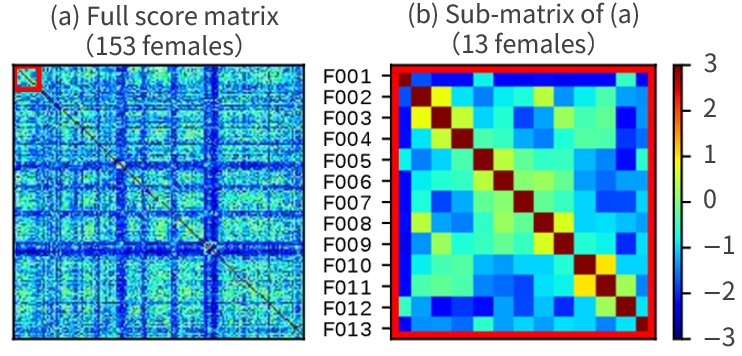
We utilize crowdsourced subjective inter-speaker similarity scores for training DNN-based speaker embedding models.
We show that the proposed algorithms can learn speaker embedding that is highly correlated with the similarity scores.
We also show that the proposed speaker embedding can improve synthetic speech quality in DNN-based multi-speaker speech synthesis.
Speech samples (in English, VAE-based speech modeling using mcep):
NAT: Natural speech.
D-VEC: Speech-recognition-based embedding.
SIM-VEC: Similarity vector embedding.
SIM-MAT: Similarity matrix embedding using ALL speaker pairs.
Method
Speaker 1
Speaker 2
Speaker 3
NAT:
D-VEC:
SIM-VEC:
SIM-MAT:
References:
Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari,
"Perceptual-similarity-aware deep speaker representation learning for multi-speaker generative modeling,"
IEEE/ACM Transactions on Audio, Speech, and Language Processing, Vol. 29, pp. 1033--1048, Feb. 2021. (IEEE Xplore)
Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari,
"Active learning for DNN-based speaker embedding considering subjective inter-speaker similarity,"
IPSJ SIG Technical Report, 2021-SLP-136, No. 30, pp. 1--6, Mar. 2021. (in Japanese, 2021 IPSJ SIG-SLP Best Student Paper Award (Yahoo! JAPAN Award)) (PDF, Slide)
Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari,
"DNN-based speaker embedding using graph embedding of subjective inter-speaker similarity,"
Proc. ASJ, Autumn meeting, 1-2-4, pp. 697--698, Sep. 2020. (in Japanese, Awaya Prize Young Researcher Award of ASJ) (PDF, Slide)
Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari,
"Evaluation of DNN-based multi-speaker speech synthesis using DNN-based speaker embedding considering subjective inter-speaker similarity,"
Proc. ASJ, Autumn meeting, 1-P-18, pp. 999--1002, Sep. 2019. (in Japanese) (PDF, Poster)
Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari,
"DNN-based speaker embedding using subjective inter-speaker similarity for multi-speaker modeling in speech synthesis,"
Proc. The 10th ISCA SSW, pp. 51--56, Vienna, Austria, Sep. 2019. (PDF, arXiv preprint, Poster)
Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari,
"DNN-based speaker embedding considering subjective inter-speaker similarity towards DNN-based speech synthesis,"
Proc. ASJ, Spring meeting, 3-10-7, pp. 1067--1070, Mar. 2019. (in Japanese) (PDF, Slide)